Learning to Generate 3D Shapes and Scenes
ECCV 2022 Workshop
Join live stream here (ECCV registration required).
Submit questions to the authors of the accepted papers: https://forms.gle/FFFVHVeTtcVkWg2n8.
Submit questions for the closing panel discussion using this google form: https://forms.gle/XADQAVR8HNavtVRj6.
Introduction
This workshop aims to bring together researchers working on generative models of 3D shapes and scenes with researchers and practitioners who use these generative models in a variety of research areas. For our purposes, we define "generative model" to include methods that synthesize geometry unconditionally as well as from sensory inputs (e.g. images), language, or other high-level specifications. Vision tasks that can benefit from such models include scene classification and segmentation, 3D reconstruction, human activity recognition, robotic visual navigation, question answering, and more.
Schedule
All times in Israel Time (UTC+03:00)
| 3:00pm - 3:15pm | Welcome and Introduction | |
| 3:15pm - 3:40pm |
Invited Talk 1 (Ruizhen Hu)
Title: Interaction Representation and Generation |
|
| 3:40pm - 4:05pm |
Invited Talk 2 (Jia Deng)
Title: Learning to Generate Synthetic Data |
|
| 4:05pm - 4:30pm | Invited Talk 3 (Zhengqi Li)
Title: Learning Infinite View Generation from Internet Photo Collections |
|
| 4:30pm - 5:25pm | Paper Spotlight Talks | |
| 5:25pm - 5:50pm |
Invited Talk 4 (Adriana Schulz)
Title: Generating Content with Computer-Aided Design (CAD) Representations |
|
| 5:50pm - 6:15pm | Invited Talk 5 (Andreas Geiger)
Title: Generating Images and 3D Shapes |
|
| 6:15pm - 7:00pm | Panel Discussion (speakers & panelists) |
Invited Speakers & Panelists

Jia Deng is an Assistant Professor of Computer Science at Princeton University. He direct the Princeton Vision & Learning Lab. His current interests include 3D vision, object recognition, action recognition, and automated theorem proving. He received his Ph.D. from Princeton University and his B.Eng. from Tsinghua University, both in computer science. He is a recipient of the Sloan Research Fellowship, the NSF CAREER award, the ONR Young Investigator award, an ICCV Marr Prize, and two ECCV Best Paper Awards.

Andreas Geiger is a Professor of computer science heading the Autonomous Vision Group (AVG). His group is part of the University of Tübingen and the MPI for Intelligent Systems located in Tübingen, Germany at the heart of CyberValley. He is deputy head of the department of computer science at the University of Tübingen, PI in the cluster of excellence `ML in Science' and the CRC `Robust Vision'. He is also an ELLIS fellow, board member, and coordinator of the ELLIS PhD program. His research group is developing machine learning models for computer vision, natural language and robotics with applications in self-driving, VR/AR and scientific document analysis.

Ruizhen Hu is an Associate Professor of College of Computer Science & Software Engineering at Shenzhen University and Deputy Director of the Visual Computing Research Center (VCC). Before coming to Shenzhen Uni- versity, she was an Assistant Researcher at Shenzhen In- stitutes of Advanced Technology (SIAT). She obtained her Ph.D. degree in Applied Math under the supervision of Prof. Ligang Liu in June 2015 from the Department of Mathematics at Zhejiang University, China. From Oct. 2012 to Oct. 2014, she spent two years visiting the GrUVi Lab in the School of Computing Science at Simon Fraser University, Canada, under the supervision of Prof. Hao (Richard) Zhang. The visit was supported by China Scholarship Council (CSC). Her research interests are in computer graphics, with a recent focus on applying machine learning to advance the understanding and generative modeling of visual data including 3D shapes and indoor scenes.

Zhengqi Li is a research scientist at Google Research. His research interests span 3D/4D computer vision, epsically for images and videos in the wild. He received his CS Ph.D. degree at Cornell University where he was advised by Prof. Noah Snavely. He received his Bachelor of Computer Engineering with High Distinction at University of Minnesota, Twin Cities where he was advised by Prof. Stergios Roumeliotis and was a research assistant at MARS Lab and Google Project Tango (now ARCore). He was also a member of Robotic Sensor Networks (RSN) Lab where he worked closely with Prof. Volkan Isler. He is a recipient of the CVPR 2019 Best Paper Hornorable Mention, 2020 Google Ph.D. Fellowship, 2020 Adobe Research Fellowship, and 2021 Baidu Global Top 100 Chinese Rising Stars in AI.

Adriana Schulz is an assistant professor at the Paul G. Allen School of Computer Science & Engineering at the University of Washington and a member of the Computer Graphics Group (GRAIL). She is also co-director of the Digital Fabrication Center at UW (DFab) and the director of WiGRAPH. Her research group creates manufacturing design systems that will revolutionize how we build physical artifacts, and builds next-generation design tools for manufacturing that fundamentally change what can be made, and by whom.
Call for Papers
Call for papers: We invite papers of up to 14 pages for work on tasks related to data-driven 3D generative modeling or tasks leveraging generated 3D content. Paper topics may include but are not limited to:
- Generative models for 3D shape and 3D scene synthesis
- Generating 3D shapes and scenes from real world data (images, videos, or scans)
- Representations for 3D shapes and scenes
- Completion of 3D scenes or objects in 3D scenes
- Unsupervised feature learning for vision tasks via 3D generative models
- Training data synthesis/augmentation for vision tasks via 3D generative models
Submission: we encourage submissions of up to 14 pages excluding references and acknowledgements. The submission should be in the ECCV format. Reviewing will be single blind. Accepted papers will be made publicly available as non-archival reports, allowing future submissions to archival conferences or journals. We welcome already published papers that are within the scope of the workshop (without re-formatting), including papers from the main ECCV conference. Please submit your paper to the following address by the deadline: 3dscenegeneration@gmail.com Please mention in your email if your submission has already been accepted for publication (and the name of the conference).
Important Dates
| Paper Submission Deadline | Sep 19 2022 - AoE time (UTC -12) |
| Notification to Authors | Sep 26 2022 |
| Camera-Ready Deadline | Oct 5 2022 |
| Workshop Date | Oct 23 2022 |
Accepted Papers

3D GAN Inversion for Controllable Portrait Image Animation
Connor Z. Lin, David B. Lindell, Eric R. Chan, Gordon Wetzstein
Paper | Poster | Video

3DLatNav: Navigating Generative Latent Spaces for Semantic-Aware 3D Object Manipulation
Amaya Dharmasiri, Dinithi Dissanayake, Mohamed Afham, Isuru Dissanayake, Ranga Rodrigo, Kanchana Thilakarathna
Paper | Poster | Video

3D Semantic Label Transfer and Matching in Human-Robot Collaboration
Szilvia Szeier, Benjámin Baffy, Gábor Baranyi, Joul Skaf, László Kopácsi, Daniel Sonntag, Gábor Sörös, and András Lőrincz
Paper | Poster | Video

Generative Multiplane Images: Making a 2D GAN 3D-Aware
Xiaoming Zhao, Fangchang Ma, David Güera, Zhile Ren, Alexander G. Schwing, Alex Colburn
Paper | Poster | Video

Intrinsic Neural Fields: Learning Functions on Manifolds
Lukas Koestler, Daniel Grittner, Michael Moeller, Daniel Cremers, Zorah Lähner
Paper | Poster | Video

Learning Joint Surface Atlases
Theo Deprelle, Thibault Groueix, Noam Aigerman, Vladimir G. Kim, Mathieu Aubry
Paper | Poster | Video
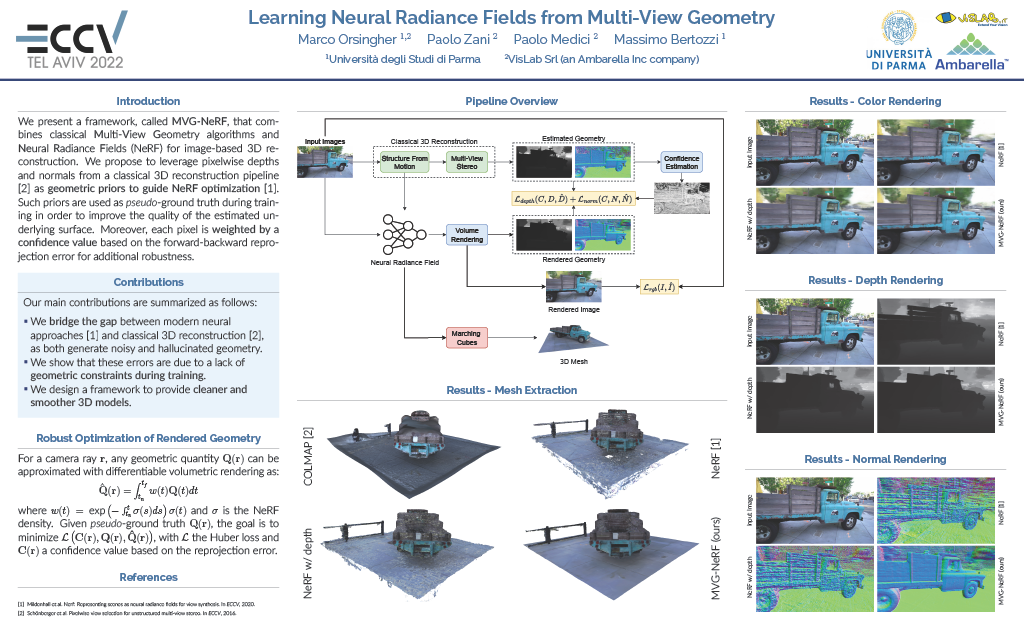
Learning Neural Radiance Fields from Multi-View Geometry
Marco Orsingher, Paolo Zani, Paolo Medici, Massimo Bertozzi
Paper | Poster | Video
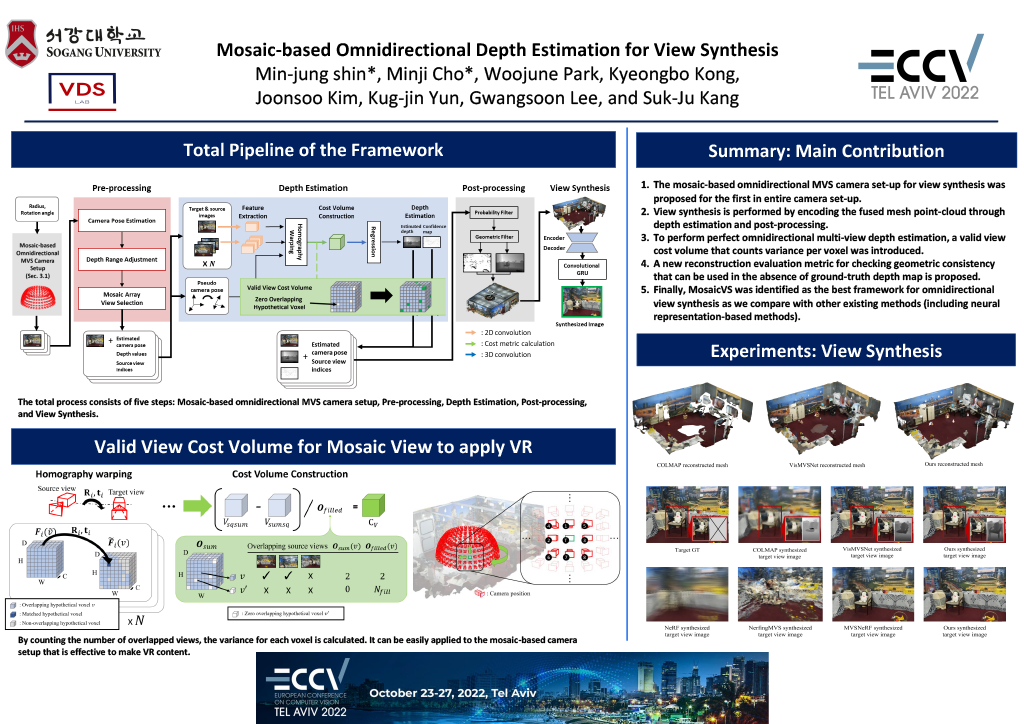
Mosaic-based omnidirectional depth estimation for view synthesis
Min-jung Shin, Minji Cho, Woojune Park, Kyeongbo Kong, Joonsoo Kim, Kug-jin Yun, Gwangsoon Lee, Suk-Ju Kang
Paper | Poster | Video

Neural Shape Compiler: A Unified Framework for Transforming between Text, Point Cloud, and Program
Tiange Luo, Honglak Lee, Justin Johnson
Paper | Poster | Video

RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
Jonathan Tremblay, Moustafa Meshry, Alex Evans, Jan Kautz, Alexander Keller, Sameh Khamis, Thomas Müeller, Charles Loop, Nathan Morrica, Koki Nagano, Towaki Takikawa, Stan Birchfield
Paper | Poster | Video

Recovering Detail in 3D Shapes Using Disparity Maps
Marissa Ramirez de Chanlatte, Matheus Gadelha, Thibault Groueix, Radomir Mech
Paper | Poster | Video

Share With Thy Neighbors: Single-View Reconstruction by Cross-Instance Consistency
Tom Monnier, Matthew Fisher, Alexei A. Efros, Mathieu Aubry
Paper | Poster | Video

Towards Generalising Neural Implicit Representations
Theo W. Costain, Victor A. Prisacariu
Paper | Poster | Video
Organizers

Brown University

Simon Fraser University

Simon Fraser University

Adobe Research, London

Brown University

Simon Fraser University
Prior workshops in this series
CVPR 2021: Learning to Generate 3D Shapes and ScenesCVPR 2020: Learning 3D Generative Models
CVPR 2019: 3D Scene Generation
Acknowledgments
Thanks to visualdialog.org for the webpage format.